Evidence Layers
What supports the research program.
Different papers use different evidence layers. The public claim is strongest when a paper combines protocol, raw logs, provenance, negative results, and explicit stop rules.
LayerEvidenceWhere usedBoundary
E0Formal definitions, protocols, equations, and claim registriesP04-P21Framework support, not empirical deployment proof
E1Longitudinal API / text-agent panels with repeated rounds and seedsP01-P04Text-agent evidence, not robot evidence
E2RLBench self-trained low-dimensional imitation baseline, 6,300 trialsP05-P06Not a public VLA/SOTA leaderboard
E3Public-factory sidecars and supported-set VLA/LIBERO evaluationP05-P07Supported-set evidence, not full benchmark domination
E4Macro mining, representation compression, and perspectival grounding registriesP08Representation-search evidence, not priority over all compression research
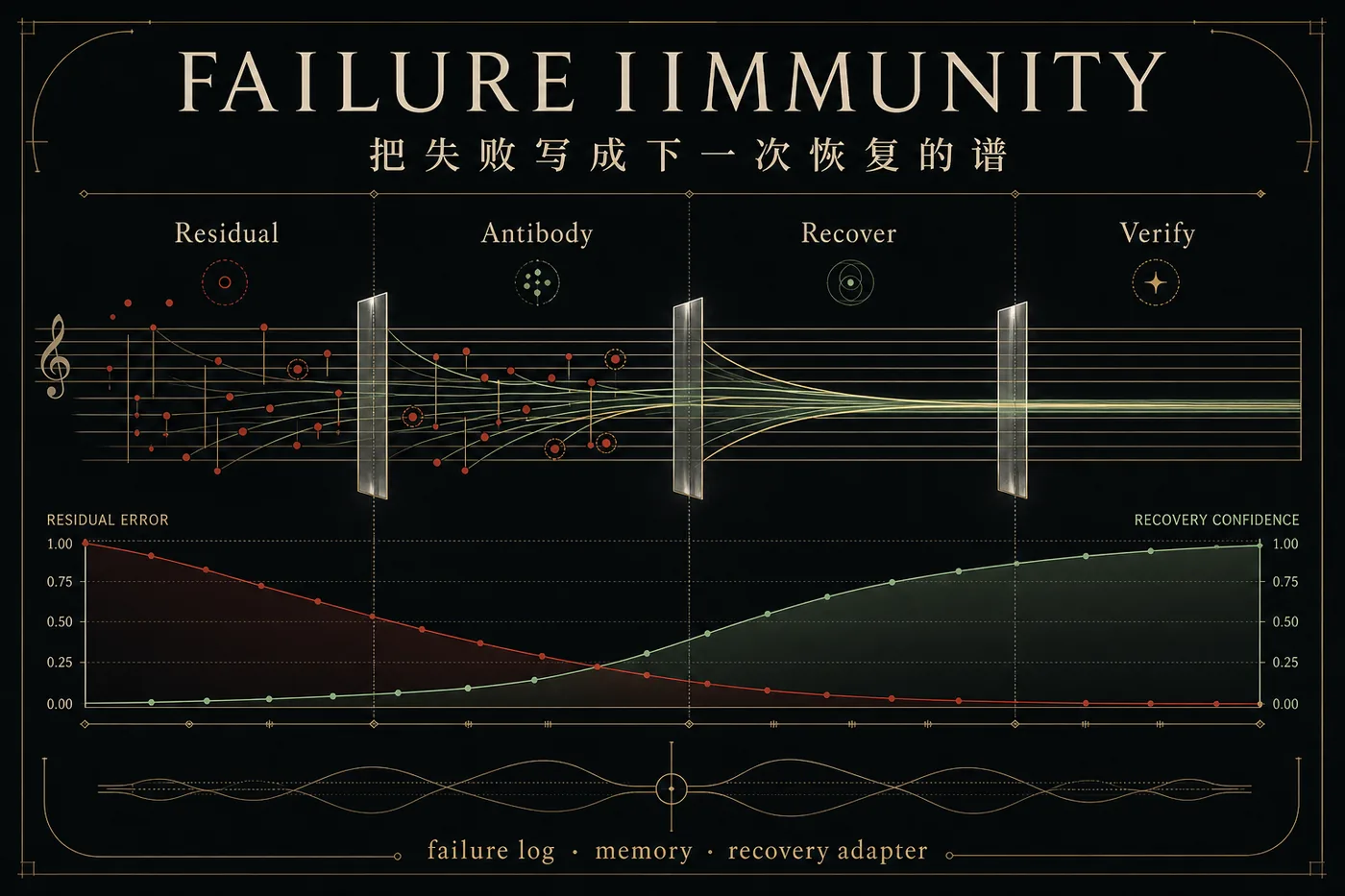
E5Failure-antigen labels, recovery-adapter pilots, and trajectory provenanceP09Offline/pilot recovery evidence, not full trained-policy improvement
E6World-model counterfactual, cybernetic, social, and supra-body ablation artifactsP10-P14Simulation and protocol evidence, not real-world deployment
E7Public simulator bridges and AI-for-science benchmark proposalsP19Benchmark framing, not climate-control authority
E8Adverse perception, detector/tracker logs, DAWN1027/COCO128/public panelsP20Robust evidence gating, not detector SOTA
E9Human-intervention residual schemas and synthetic/public teleoperation ingestionP21No human-subject or wearable-robot validation yet